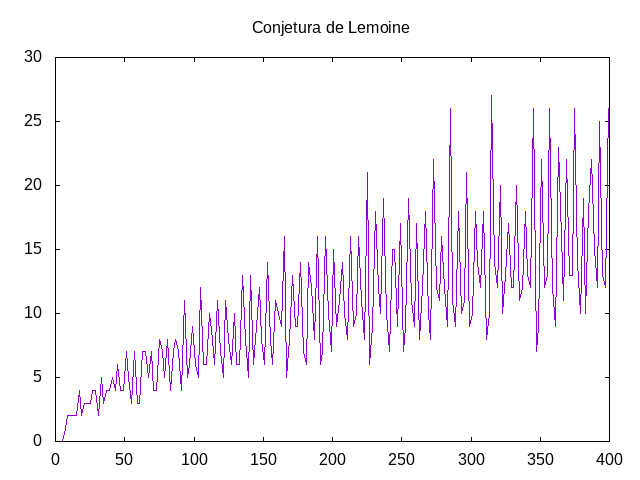
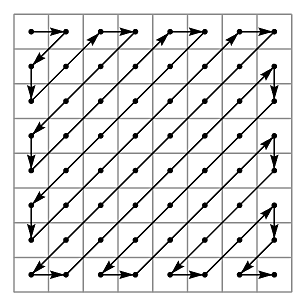
El problema de las N reinas consiste en colocar N reinas en tablero rectangular de dimensiones N por N de forma que no se encuentren más de una en la misma línea: horizontal, vertical o diagonal. Por ejemplo, una solución para el problema de las 4 reinas es
Los estados del problema de las N reinas son los tableros con las reinas colocadas. Inicialmente el tablero está vacío y, en cda paso se coloca una reina en la primera columna en la que aún no hay ninguna reina.
Cada estado se representa por una lista de números que indican las filas donde se han colocado las reinas. Por ejemplo, el tablero anterior se representa por [2,4,1,3].
λ> putStrLn (drawTree (fmap show (arbolReinas 4)))
[]
|
+- [1]
| |
| +- [3,1]
| |
| `- [4,1]
| |
| `- [2,4,1]
|
+- [2]
| |
| `- [4,2]
| |
| `- [1,4,2]
| |
| `- [3,1,4,2]
|
+- [3]
| |
| `- [1,3]
| |
| `- [4,1,3]
| |
| `- [2,4,1,3]
|
`- [4]
|
+- [1,4]
| |
| `- [3,1,4]
|
`- [2,4]
λ> putStrLn (drawTree (fmap show (arbolReinas 5)))
[]
|
+- [1]
| |
| +- [3,1]
| | |
| | `- [5,3,1]
| | |
| | `- [2,5,3,1]
| | |
| | `- [4,2,5,3,1]
| |
| +- [4,1]
| | |
| | `- [2,4,1]
| | |
| | `- [5,2,4,1]
| | |
| | `- [3,5,2,4,1]
| |
| `- [5,1]
| |
| `- [2,5,1]
|
+- [2]
| |
| +- [4,2]
| | |
| | `- [1,4,2]
| | |
| | `- [3,1,4,2]
| | |
| | `- [5,3,1,4,2]
| |
| `- [5,2]
| |
| +- [1,5,2]
| | |
| | `- [4,1,5,2]
| |
| `- [3,5,2]
| |
| `- [1,3,5,2]
| |
| `- [4,1,3,5,2]
|
+- [3]
| |
| +- [1,3]
| | |
| | `- [4,1,3]
| | |
| | `- [2,4,1,3]
| | |
| | `- [5,2,4,1,3]
| |
| `- [5,3]
| |
| `- [2,5,3]
| |
| `- [4,2,5,3]
| |
| `- [1,4,2,5,3]
|
+- [4]
| |
| +- [1,4]
| | |
| | +- [3,1,4]
| | | |
| | | `- [5,3,1,4]
| | | |
| | | `- [2,5,3,1,4]
| | |
| | `- [5,1,4]
| | |
| | `- [2,5,1,4]
| |
| `- [2,4]
| |
| `- [5,2,4]
| |
| `- [3,5,2,4]
| |
| `- [1,3,5,2,4]
|
`- [5]
|
+- [1,5]
| |
| `- [4,1,5]
|
+- [2,5]
| |
| `- [4,2,5]
| |
| `- [1,4,2,5]
| |
| `- [3,1,4,2,5]
|
`- [3,5]
|
`- [1,3,5]
|
`- [4,1,3,5]
|
`- [2,4,1,3,5]
λ> soluciones 4
[[3,1,4,2],[2,4,1,3]]
λ> soluciones 5
[[4,2,5,3,1],[3,5,2,4,1],[5,3,1,4,2],[4,1,3,5,2],[5,2,4,1,3],
[1,4,2,5,3],[2,5,3,1,4],[1,3,5,2,4],[3,1,4,2,5],[2,4,1,3,5]]